
Немного об ClickHouse
Настал тот час когда прилетел интересный task по разворачиванию ClickHouse для бекенд команды. Все мы знаем, что пихать базы данных в kubernetes не есть бест практис, особенно для продакшена!!! Но мы будем не мы, если не попробуем развернуть его в kubernetes =).
В пределах этого поста не будем глубоко погружаться в работу и структуру данной базы, немножко поговорим про сам ClickHouse, особенности, терминологию и перейдем к оператору.
ClickHouse – если кратко, это столбовая система управления базами данных для онлайн обработки аналитических запросов. Очень хорошим плюсом есть то что он умеет отдавать метрики из коробки, останется только указать прометеусу откуда собирать метрики и все должно взлететь.
Данные в СlickHouse хранятся в столбцах (взято с офф документации):
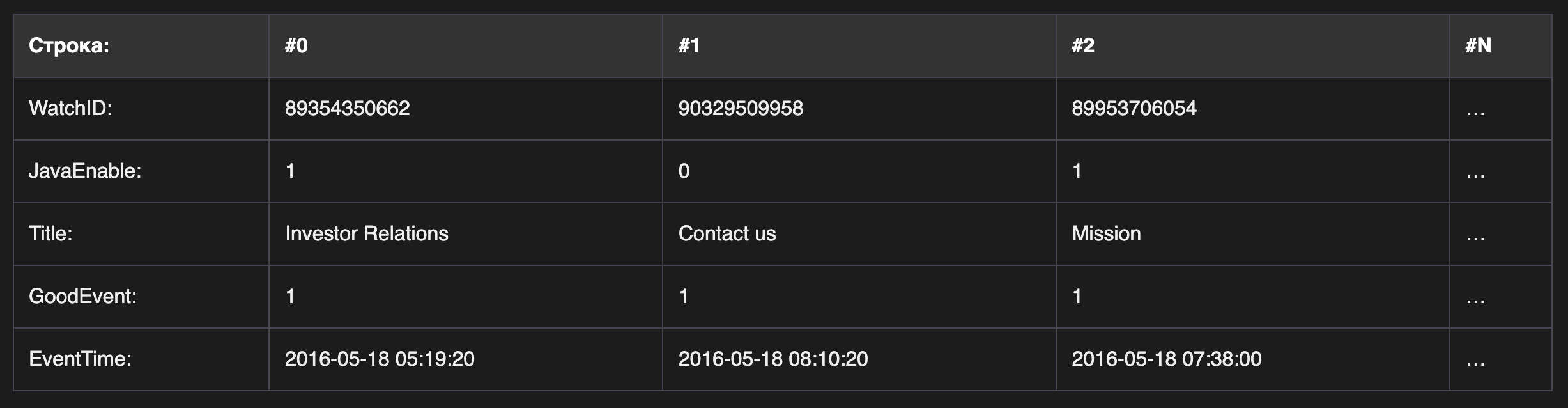
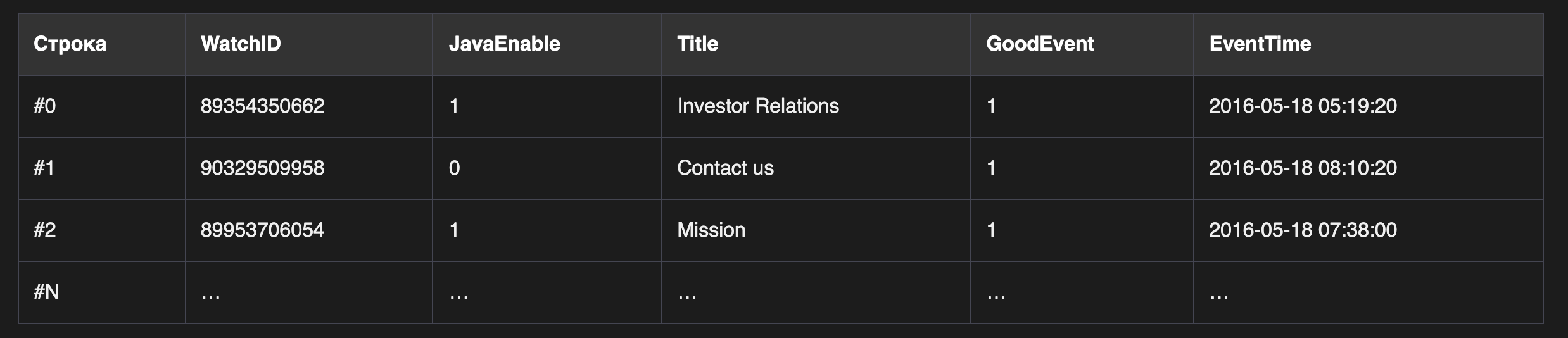
в то время как в обычных SQL базах в строках(на изображении показан только порядок расположения данных):
Особенности:
– сжатие данных
– прекрасно работает на простых жёстких дисках
– большие запроси распределяться, используя все необходимые ресурсы на сервере доступных
– поддержка SQL
– данные обновляться в реальном времени
– прекрасно подходит для онлайн запросов и еще много чего….
– репликация данных
Для работы с ClickHouse представлены два интерфейса, которые можно обернуть в TLS если нужна дополнительная безопасность:
– TCP: по умолчанию 9000 (используется для доступа на прямую)
– HTTP: по умолчанию 8123 (то есть ми можем делать GET or POST запроси в базу используя curl и не только)
Перед тем как приступим к разворачиванию оператора и настройки нашего первого кластера заденем два популярных термина это шардирование и репликация. Все это нам понадобиться для общего понимания и дальнейшей настройки.
Шардирование
Шардирование – горизонтальное масштабирование кластера, при котором разные части одной базы распределяются на разные шарды. Шард состоит из одного или нескольких хостов. Выделенного мастера нет, по этому запись или чтение происходит с любой реплики.
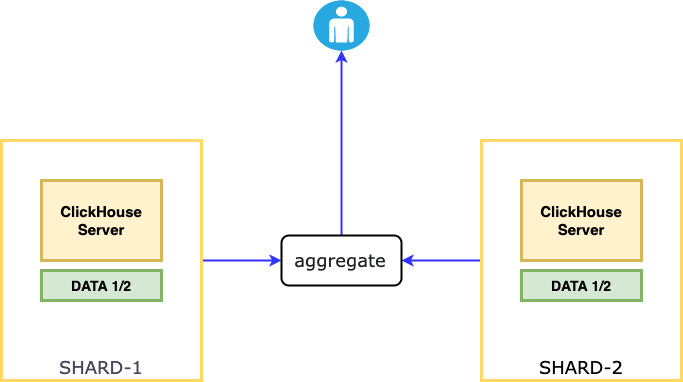
На примере показано два сервера(пода), на каждом сервере созданы одинаковее таблицы. Данные при записи разделяются на некоторые части, часть данных записывается в один шард, а половину во второй. Для примера есть табличка с 6 миллионами записей, мы можем разместить 3 миллиона на первый шард и три на второй, когда обратиться пользователь, данные собираются, агрегируются(суммируются, объединяются), отправляются пользователю.
Для реализации шардирования существует Engine=Distributed дистрибьютор таблиц. В ClickHouse таблицы можно разделить на виртуальнее или реальные.
– реальные: хранят физически данные на дисках
Engine = MergeTree
– виртуальные: ничего не хранят
Engine = Distributor
Движок дистрибьютор позволяет собрать данные с разных шардов, обєдинить их, посчитать количество и отдать пользователю, подробнее про движки можно почитать здесь. Стоит помнить, что он в себе ничего не хранит.
Все настройки производиться на уровне таблиц, clickhouse не использует модель репликации instance – instance, репликацию и шардирование нужно настраивать на уровне таблиц. Теперь немного поговорим об репликации.
Репликация
Репликация внутри шарда используются для отказоустойчивости и распараллеливания чтения. Если говорить про распараллеливание, то здесь мы можем отправлять первый запрос в одном шарде на первый сервер, после чего с этого же шарда отправить запрос на второй сервер. Репликация работает только для отдельных таблиц с использованием движка MergeTree.
Для настройки репликации используется zookeeper. Зукипер содержит в себе информацию о реплицируемых таблицах, его можно поднимать на отдельных серверах ири размещать на сервере с ClickHouse.
Кратко о том как работает зукипер. Он постоянно забирает себе актуальные данные с реплик, по этому все репликации смотрят на него. Когда реплика видит что в зукипере появились новые данные, она идет на прямую в реплику и скачивает их себе. Когда реплика данные забрала, зукипер отмечает в себе что данные благополучно забрали.
Таким образом если реплика вышла из строя, она подключается к зукиперу, находит все необходимые данные которые ей нужны. Когда есть нужные данные или их части, реплика идет на работающую реплику (в которой данные есть) и скачивает их себе.
Рекомендуют Зукипер использовать для хранения только состояния репликаций и выносить на отдельные ноды. Так как он тоже кушает системные ресурсы и когда падает, начинаются проблемы с репликацией. Подробнее как установить Зукипер и базовая его настройка смотрим здесь
Установка
Документация – https://docs.altinity.com/clickhouseonkubernetes/
Репозиторий оператора – https://github.com/Altinity/clickhouse-operator/blob/master/docs/
clickhouse-operetor – open source проект, который облегчает работу администраторам и devops инженерам, так как часть рутинной работы, микро менеджменту и администрированию кластера забирает на себя. Что в свою очередь позволяет не вдаваться в подробности (как там внутри все работает). Мы просто даем ему высокоуровневые задачи и он их выполняет.
Оператор сопровождает весь жизненный цикл работы кластера. Выполняя ежедневные задачи по масштабированию, шардированию, изменению конфигураций и прочего.
Пример следующих задач которые умеет делать оператор:
– конфигурирование ClickHouse
– добавление и удаление шардов и реплик
– обновление нод кластера
– мониторинг состояния кластера
– при необходимости удаляет кластер

Для начала установим сам оператор, далее опишем примитивный PoC single-node ClickHouse, а после развернем его используя оператор.
Сами разработчики в докладах рекомендуют использовать kubectl для установки в обход helm. Потому что при установке через kubectl получаем гибкое и более автоматизированное администрирование чем при установке helm, но никто не запрещает его использовать. В нашем случае воспользуюсь kubectl.
clickhouse-operator
Заранее забегу наперед, в процессе установки и тестирования заметил особенность: если устанавливать оператор в неймспейс kube-system – кластер можно создавать в любом неймспейсе, но, если установить в другой ns – тогда кластер нужно устанавливать в той же неймспейс где и сам оператор! Рекомендую перед установкой ознакомиться с содержимым манифеста, посмотреть расширенную настройку и только тогда устанавливать.
В операторе есть дефолтный пользователь, его использует оператор для доступа к метрикам, базам и тд, посмотреть можно в манифестах установки. По-хорошему, нужно скачать сам манифест, подправить пароль и имя пользователя(если нужно) после устанавливать, или изменить пароль после установки, выбор за Вами).
Пример пользователя с манифеста clickhouse-operator-install-bundle.yaml:
# ClickHouse credentials (username, password and port) to be used by operator to connect to ClickHouse instances
# for:
# 1. Metrics requests
# 2. Schema maintenance
# 3. DROP DNS CACHE
# User with such credentials can be specified in additional ClickHouse .xml config files,
# located in `chUsersConfigsPath` folder
chUsername: "clickhouse_operator"
chPassword: "clickhouse_operator_password"Устанавливать будем манифест с именем clickhouse-operator-install-bundle.yaml в kube-system неймспейс, варианты других установок здесь:
$ kubectl apply -f https://raw.githubusercontent.com/Altinity/clickhouse-operator/master/deploy/operator/clickhouse-operator-install-bundle.yaml
customresourcedefinition.apiextensions.k8s.io/clickhouseinstallations.clickhouse.altinity.com created
customresourcedefinition.apiextensions.k8s.io/clickhouseinstallationtemplates.clickhouse.altinity.com created
customresourcedefinition.apiextensions.k8s.io/clickhouseoperatorconfigurations.clickhouse.altinity.com created
serviceaccount/clickhouse-operator created
clusterrole.rbac.authorization.k8s.io/clickhouse-operator-kube-system created
configmap/etc-clickhouse-operator-files created
configmap/etc-clickhouse-operator-confd-files created
configmap/etc-clickhouse-operator-configd-files created
configmap/etc-clickhouse-operator-templatesd-files created
configmap/etc-clickhouse-operator-usersd-files created
deployment.apps/clickhouse-operator created
service/clickhouse-operator-metrics createdпроверяем статус оператора:
$ kubectl -n kube-system get pod | grep clickhouse clickhouse-operator-869bcd74cf-78c8n 2/2 Running 0 2d10h
Отлично, с установкой не возникло никаких проблем, идем далее.
ClickHouse Кластер
Теперь нужно описать как должен выглядеть наш кластер, после чего задеплоить его. Создадим простой в один шард, без реплик, без зукипера, но с PVC. В таком сетапе разработчики должны ознакомляться с ним, и после тестирования будем иметь полную картину какой ClickHouse нам нужно разворачивать на проде.
Для этого перейдем в репозиторий оператора где есть очень много примеров разных конфигураций (посмотреть их можно здесь).
Что мне понравилось, есть разные вариации, ми можем создавать несколько шаблонов (pvc, users, etc), устанавливать и потом подключать при создании кластера, или всю конфигурацию описать в одному манифесте. Второй вариант больше подходит, потому что в одному манифесте у нас будет все необходимое для работы кластера в одном файле.
Для хранения данных будем использовать Persistent Storage. Коротко и доходчиво по Storage в операторе описано здесь, разработчики постарались облегчить нам жизнь и сделали шаблоны на любой вкус. Рекомендується использовать тип стореджа local, потому что сейчас локальные пути на дисках инкапсулируются в сам kubernetes, что облегчает всем жизнь, а раньше доводилось все делать руками, указывать пути.
После просмотра примеров, создал файл backend-clickhouse-single-node.yaml в котором описал свой кластер с некоторыми параметрами, получилось как то так:
apiVersion: "clickhouse.altinity.com/v1"
kind: "ClickHouseInstallation"
metadata:
name: "backend"
spec:
defaults:
templates:
podTemplate: clickhouse-stable
dataVolumeClaimTemplate: data-volume
serviceTemplate: svc-template
configuration:
users:
# Admin user
# имя_пользователя/*
admin/profile: "default"
admin/password: "******"
admin/quota: "default"
admin/networks/ip: "::/0"
# read-only user
readonly/password: "******"
readonly/profile: "readonly"
readonly/quota: "default"
readonly/networks/ip: "::/0"
clusters:
- name: "shard"
layout:
shardsCount: 1
templates:
# здесь передаем кастомное описание необходимых нам компонентов используя щаблоны
podTemplates:
- name: clickhouse-stable
metadata:
labels:
custom.label: "label.backend-db"
spec:
containers:
- name: clickhouse
image: yandex/clickhouse-server:21.8
resources:
requests:
cpu: "1000m"
serviceTemplates:
- name: svc-template
generateName: chendpoint-{chi}
metadata:
labels:
custom.label: "custom.test"
annotations:
service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0
spec:
# ограничиваем доступ к LoadBalancer офисными IP
loadBalancerSourceRanges:
- ***.***.**9.*4/29
- 1**.4*.2**.***/32
ports:
- name: http
port: 8123
- name: tcp
port: 9000
type: LoadBalancer
volumeClaimTemplates:
- name: data-volume
spec:
storageClassName: gp2
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Giсоздадим неймспейс и задеплоим манифест:
$ kubectl create ns *****-backend-clickhouse-** namespace created $ kubectl -n *****-backend-clickhouse-** apply -f backend-clickhouse-single-node.yaml clickhouseinstallation.clickhouse.altinity.com/backend configured
проверим статус кластера:
$ kubectl -n *****-backend-clickhouse-** get chi NAME CLUSTERS HOSTS STATUS backend 1 1 Completed
посмотрим на сервис:
$ kubectl -n *****-backend-clickhouse-** get svc chendpoint-backend LoadBalancer 172.20.175.27 *****************************-*************.us-east-2.elb.amazonaws.com 8123:32394/TCP,9000:30769/TCP 3d chi-backend-shard-0-0 ClusterIP None <none> 8123/TCP,9000/TCP,9009/TCP 3d
где:
– chendpoint-backend – сервис с типом LoadBalancer который дает доступ ко всем шардам, доступен из мира, но ми закрыли его ограничив доступ офисными IP.
– chi-backend-shard-0-0 – сервис нашего шарда.
Проверим доступ с офиса используя curl:
$ curl *****************************-*************.us-east-2.elb.amazonaws.com:8123 Ok
хорошо, теперь переключимся на другого провайдера и посмотрим, будет ли доступ:
$ curl *****************************-*************.us-east-2.elb.amazonaws.com:8123
curl: (7) Failed to connect to *****************************-*************.us-east-2.elb.amazonaws.com:8123 : Operation timed outкак видим доступа нет.
Подключение к ClickHouse
Теперь остается вопрос, как же подключаться к clickhouse? Если говорить про внешнее подключение есть много разных GUI IDE которые рекомендует сам ClickHouse, но для тестов нам хватит clickhouse-cli, установим его:
$ pip3 install clickhouse-cli DEPRECATION: Configuring installation scheme with distutils config files is deprecated and will no longer work in the near future. If you are using a Homebrew or Linuxbrew Python, please see discussion at https://github.com/Homebrew/homebrew-core/issues/76621 Collecting clickhouse-cli Downloading clickhouse-cli-0.3.7.tar.gz (41 kB) ........
посмотрим доступные ключи и попробуем подключиться с офиса по внешнему url service alb:
$ clickhouse-cli --help Usage: clickhouse-cli [OPTIONS] [FILES]... A third-party client for the ClickHouse DBMS. Options : -h, --host TEXT Server host, set to https://<host>:<port> if you want to use HTTPS -p, --port INTEGER Server HTTP/HTTPS port -u, --user TEXT User -P, --password Ask for a password in STDIN -B, --arg-password TEXT Argument as a password -d, --database TEXT Database -s, --settings TEXT Query string to be sent with every query -c, --cookie TEXT Cookie header to be sent with every query -q, --query TEXT Query to execute -f, --format TEXT Data format for the interactive mode -F, --format-stdin TEXT Data format for stdin/file queries -m, --multiline Enable multiline shell --stacktrace Print stacktraces received from the server. --vi-mode Enable Vi input mode --version Show the version and exit. --help Show this message and exit.
подключаемся:
$ clickhouse-cli -h *****************************-*************.us-east-2.elb.amazonaws.com -u **** -P Password: clickhouse-cli version: 0.3.7 Connecting to *****************************-*************.us-east-2.elb.amazonaws.com:8123 Connected to ClickHouse server v21.8.11. :)
Для доступа внутри кластера нужно использовать внутренний кубернетес local DNS, пример такого URL:
# Template SERVICE-NAME.NAMESPACE.svc.cluster.local # example chendpoint-backend.*****-backend-clickhouse-**.svc.cluster.local
провалимся в под приложения, которое находиться в неймспейсе ***-qa-***-** и постучимся курлом:
root@test-65d8bc74d-pf59c:/# curl chendpoint-backend.*****-backend-clickhouse-**.svc.cluster.local:8123 Ok.
теперь с єтого же пода, но используя clickhouse-cli:
root@test-65d8bc74d-pf59c:/# clickhouse-cli -h chendpoint-backend.*****-backend-clickhouse-**.svc.cluster.local -u admin -P Password: clickhouse-cli version: 0.3.7 Connecting to chendpoint-backend.*****-backend-clickhouse-**.svc.cluster.local:8123 Connected to ClickHouse server v21.8.11. :)
Проверка Storage
Проверим PVC, создадим тестовую базу с табличкой, зальем туда данные, после удалим под, дождемся когда поднимется новый и проверим наличие данных.
посмотрим на PVC:
$ kubectl -n ****-backend-clickhouse-** get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-volume-chi-backend-shard-0-0-0 Bound pvc-f38912c9-7716-4039-a1b8-aa589aedfeb2 10Gi RWO gp2 77mподключимся в под и глянем путь монтирования:
$ kubectl -n ****-backend-clickhouse-** exec -it chi-backend-shard-0-0-0 -- bash
root@chi-backend-shard-0-0-0:/# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 200G 14G 187G 7% /
tmpfs 64M 0 64M 0% /dev
tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
/dev/nvme0n1p1 200G 14G 187G 7% /etc/hosts
shm 64M 0 64M 0% /dev/shm
/dev/nvme1n1 9.8G 181M 9.6G 2% /var/lib/clickhouse # вот он
tmpfs 3.8G 12K 3.8G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 3.8G 0 3.8G 0% /proc/acpi
tmpfs 3.8G 0 3.8G 0% /sys/firmwarestorage подключен.
Подключаемся к кластеру ClickHouse, смотрим какие базы сейчас есть:
$ kubectl -n ******-backend-clickhouse-** exec -it chi-backend-shard-0-0-0 -- clickhouse client
ClickHouse client version 21.8.11.4 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 21.8.11 revision 54449.
chi-backend-shard-show databases;
SHOW DATABASES
Query id: 311eaa63-6075-4d87-8983-8cce42b53dbb
┌─name────┐
│ default │
│ system │
└─────────┘
2 rows in set. Elapsed: 0.002 sec.Создадим тестовую с именем testdb:
:) create database testdb;
CREATE DATABASE testdb
Query id: 6cf92d0f-794e-4448-8f1f-1c0059ab289a
Ok.
0 rows in set. Elapsed: 0.003 sec.
:) use testdb;
USE testdb
Query id: 60c41186-7720-4149-b287-3e89132f592e
Ok.
0 rows in set. Elapsed: 0.001 sec.теперь таблицу с именем test:
:) CREATE TABLE testdb.test AS system.one ENGINE = Distributed('shard', 'system', 'one');
CREATE TABLE testdb.test AS system.one ENGINE = Distributed('shard', 'system', 'one')
Ok. 0 rows in set. Elapsed: 0.019 sec. Processed: 0 rows, 0.0B (0 rows/s, 0.0B/s)
:) select * from testdb.test;
select *
from testdb.test
┌─dummy─┐
│ 0 │
└───────┘
Ok. 1 row in set. Elapsed: 0.006 sec. Processed: 0 rows, 0.0B (0 rows/s, 0.0B/s)Удаляем под и ждем когда поднимется новый:
$ kubectl -n ******-backend-clickhouse-** delete pod chi-backend-shard-0-0-0
pod "chi-backend-shard-0-0-0" deletedподключаемся снова к базу, проверяем доступность данных:
:) show databases; show databases ┌─name────┐ │ default │ │ system │ │ test │ │ testdb │ └─────────┘ Ok. 4 rows in set. Elapsed: 0.008 sec. Processed: 0 rows, 0.0B (0 rows/s, 0.0B/s) :) select * from testdb.test; select * from testdb.test ┌─dummy─┐ │ 0 │ └───────┘ Ok. 1 row in set. Elapsed: 0.010 sec. Processed: 0 rows, 0.0B (0 rows/s, 0.0B/s) :)
Отлично, все сохранились.
Что ж, первоначальный сетап готов. Мы установили кластер в один шард, создали два пользователя, один pvc для хранения данных, осталось продумать как делать бекап и восстановление, мониторинг, автоматизацию для установки оператора, создания и изменения кластеров для разных команд.
Полезные ссылки
– Оператор в Kubernetes для управления кластерами БД.
– clickhouse documentation
– https://docs.altinity.com/clickhouseonkubernetes/
– https://github.com/Altinity/clickhouse-operator/tree/master/docs/chi-examples
– https://cloud.yandex.ru/docs/managed-clickhouse/concepts/sharding
– https://cloud.yandex.ru/docs/managed-clickhouse/concepts/replication