
Описание
Процес установки Grafana, Influxdb, Jmeter в kubernetes описывать не стану, так как взял уже готовый чарт https://github.com/kaarolch/kubernetes-jmeter, который установил используя Jenkins.
В нем есть:
- Dockerfile c Jmeter
- скрипт запуска тестов, helm-chart, Grafana, Influxdb которые можно модифицировать под себя.
- добавлен dashboard который импортируется при установк
- добавил несколько плагинов для JmeterMaster в Dockerfile.
Задание состоит в том, чтоб автоматизировать запуск нагрузочного тестирования, так как сейчас делаем все руками. На основе собранной информации от команд прикинул приблизительный план реализации:
- Запуск скрипта
Groovy cкрипт будем запускать в docker образе, в котором установлен kubectl, aws-cli, helm, helm-secret, sops; - Создание и Удаление ресурсов
Должна быть возможность создавать и удалять RDS Cluster, который будет использовать тестовая апка. Так как после создания нужно заливать данные на созданный кластер, а это очень долгий процесс, такой вариант не подходит. Оптимальным решением вижу восстанавливать кластер со снапшота.Добавим возможность создания и удаление только тогда когда нам это необходимо, используя Boolean Parameter. Стейдж создание назовем CREATE_RDS_CLUSTER и разместим его в начале скрипта, а удаление DELETE_RDS_CLUSTER разместив в конце. - Доступы
Для доступа к AWS RDS, EKS, KMS нужен IAM пользователь с необходимыми правами.
Данные пользователя передаем через параметры c именем AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY.
- Хранение тест план файлов
Хранить будем в отдельном GitHub репозитории. Файл JMX содержит токены и пароли которые нужны для тестов, их нужно убрать и передавать через Jenkins, но есть одно, но, так файл будет очень часто изменяться, будут добавляться новые параметры – передавать через Jenkins не выйдет (прийдется постоянно изменять пайплайн).
По этому файл шифруем и храним в шифрованном виде. Активно используем helm-secret под капотом которого работает sops, по этому используем сам sops. В данном случае нужно настраивать каждому QA aws profile с доступом к kms, чтоб они могли шифровать и дешифровать файлы. - Параметры
Пароли, секреты будем передавать через password parameters, а остальные как string parameters. QA команда должна иметь возможность передавать их через Jenkins Job.
Ниже список основных параметров которые будем использовать:
- Репозиторий и ветку с тестовыми файлами – QA_REPO_URL, QA_REPO_BRANCH.
- Выбор кластера и неймспейса в котором задеплоен jmeter – AWS_EKS_CLUSTER, AWS_EKS_NAMESPACE.
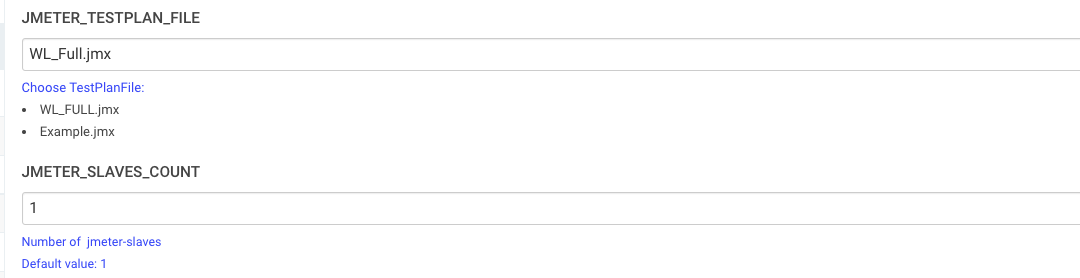
- Количество jmeter-slaves – JMETER_SLAVES_COUNT.
- Выбор нужного JMX файла – JMETER_TESTPLAN_FILE.
- Уменьшение и увеличение jmeter-slave. Здесь должна быть возможность указывать нужное количество pod. Для реализации воспользуемся kubectl scale deployment которому через string parameter с именем JMETER_SLAVES_COUNT будем передавать нужное количество подов.
- Подготовка и Запуск тестов
Jmeter в нашем сетапе не имеет GUI, недоступный из вне, доступ только внутри кластера. Как запускать тесты? Оптимальным вариантом вижу использования kubectl.
Напишем stage(“Copy FileJMX to Jmeter-Master”) который будет дешифровать файл, после чего копировать его используя kubectl cp в pod с jmeter-master, после в stage(“Scale Up Jmeter-Slaves”) наскейлим нужное количество подов и запустим тесты в stage(“Run LoadTesting”) используя kubectl exec. - Просмотр результатов
Нужно выводить результат тестирования в конце задания. Результаты отображаются в Grafana, по этому в конце вижу смысл добавить stage(“ShowTestResult”) где будем выводить URL на Grafana Dashboard с указанным интервалом времени (начало и окончание тестования).
За период времени в URL отвечает &from=***&to=***. Останется только придумать как подставлять время.
Приступим к практике. Полную версию пайплайна можно скачать здесь.
Написание groovy
Создание RDS Cluster
Создадим в Jenkins задание с типом pipeline назвав его jmeter-load-testing. Добавим в него Boolean Parameter чтоб при активации он восстанавливал базу со снапшота и добавлял CNAME в Route53:
jmeter-load-testing –> This project is parameterized –> Add Parameters –> Boolean Parameter, назовем параметр CREATE_RDS_CLUSTER и добавим описание: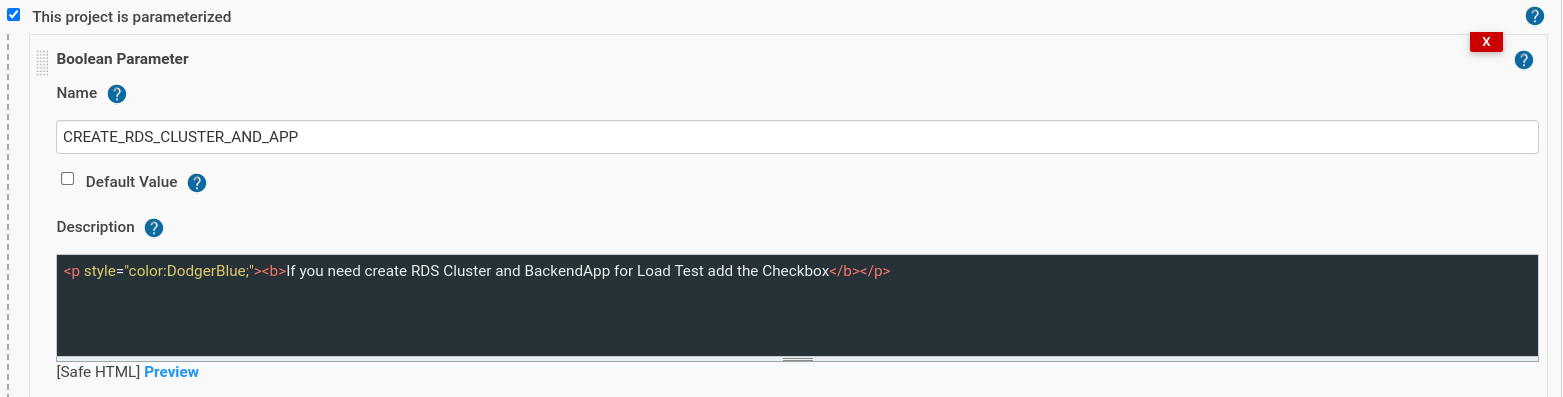
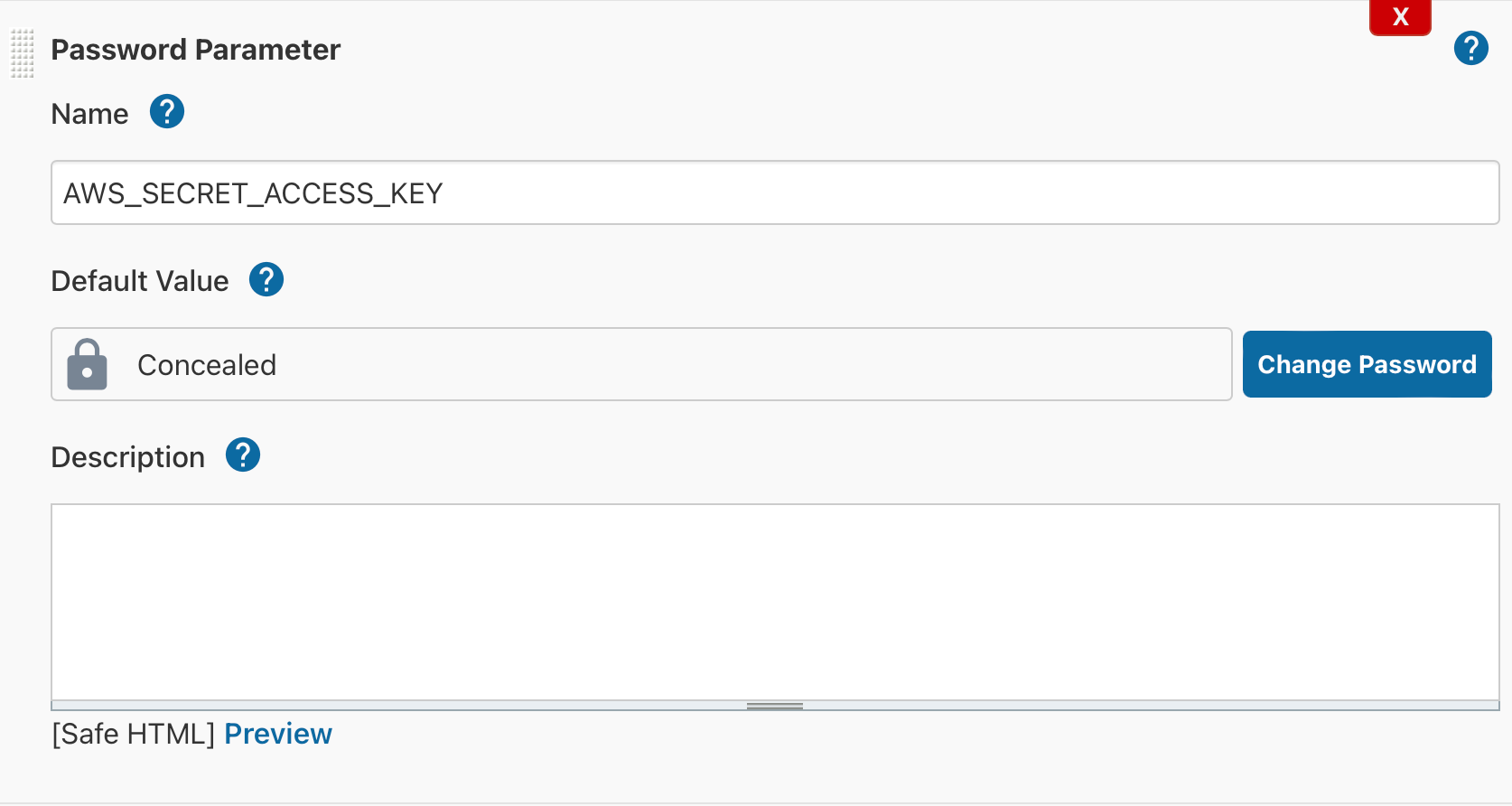
Для доступа к ресурcам AWS нужно передавать AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, использовать их будем как переменною при запуске контейнера: 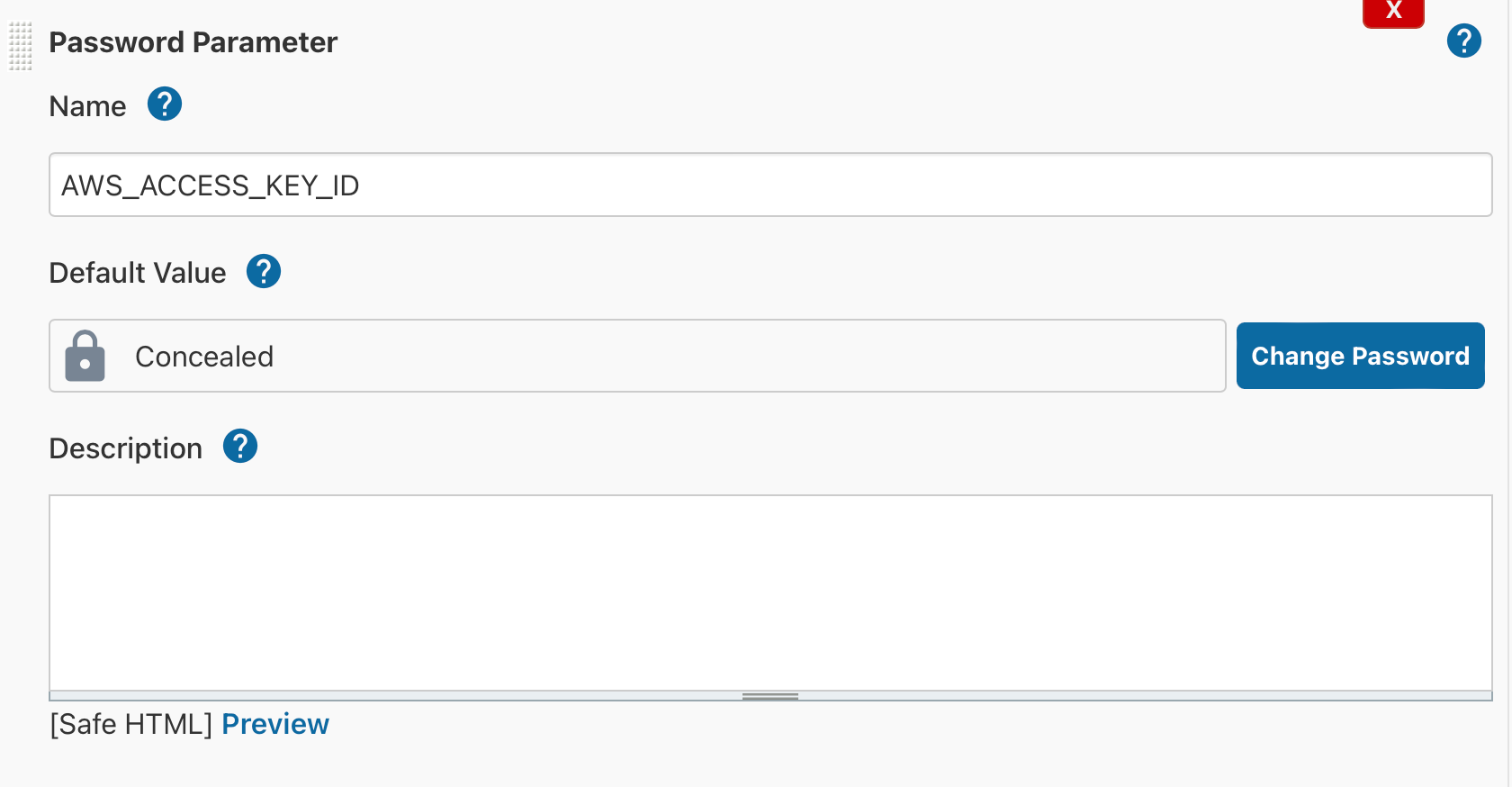
Переходим к скрипту. Добавим условие создания RDS:
if (env.CREATE_RDS_CLUSTER_AND_APP.toBoolean()){
// some code
}Когда условие будет true (поставлена галка в боксе), используя aws-cli будем восстанавливать RDS кластер со снапшота. При восстановлении кластера нужно придерживаться последовательности восстановления.
Сначала поднимаем сам кластер aws rds restore-db-cluster-from-snapshot а после создаем два инстанса (writer and reader) используя команды aws rds create-db-instance. В конце добавим aws rds wait db-instance-available и будем ждать когда кластер будет доступный.
Для поиска последнего снапшота добавим функцию def rdsSnapshot(){} (функции нужно размещать над блоком node(”){}) которая будет выводить список всех snapshots, после чего сортировать по нужному имени и оставлять только самый последний убрав все лишнее, приступим:
def rdsSnapshot(){
snapshot = sh (returnStdout: true, script:"aws rds describe-db-cluster-snapshots --query 'DBClusterSnapshots[].DBClusterSnapshotIdentifier[]' | grep rds:************ | cut -b 6-44 | tr -d '\n'")
}
node('master'){
docker.image('******/kubectl-aws:4.8').inside("-v /var/run/docker.sock:/var/run/docker.sock -e AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} -e AWS_SECRET_ACCESS_KEY=${AWS_ACCESS_KEY_ID} -e AWS_DEFAULT_REGION=us-east-2"){
if (env.CREATE_RDS_CLUSTER_AND_APP.toBoolean()){
stage("RDS: CreateLoadTestDB"){
rdsSnapshot()
echo "============================== Restore DB Cluster ==================================="
sh "aws rds restore-db-cluster-from-snapshot \
--snapshot-identifier ${snapshot} \
--engine aurora-mysql \
--engine-version 5.7.mysql_aurora.2.07.2 \
--vpc-security-group-ids sg-096********6ed \
--db-cluster-identifier loadtest-aurora-backend-dev \
--db-subnet-group-name default-vpc-************* \
--db-cluster-parameter-group-name ****-****-***-stack-parametergroup"
echo "================================ Create DB writer ====================================="
sh "aws rds create-db-instance \
--engine aurora-mysql \
--publicly-accessible \
--db-cluster-identifier loadtest-aurora-backend-dev \
--db-instance-identifier loadtest-aurora-backend-dev-instance-1 \
--db-instance-class db.r5.large"
echo "================================ Create DB reader ====================================="
sh "aws rds create-db-instance \
--publicly-accessible \
--engine aurora-mysql \
--db-cluster-identifier loadtest-aurora-backend-dev \
--db-instance-identifier loadtest-aurora-backend-dev-instance-2 \
--db-instance-class db.r5.large"
echo "========================== Wait when DB have been created ==========================="
sh "aws rds wait db-instance-available --db-instance-identifier loadtest-aurora-backend-dev-instance-1"
sh "aws rds wait db-instance-available --db-instance-identifier loadtest-aurora-backend-dev-instance-2"
}
stage("Route53: Create Record"){
sh"""aws route53 change-resource-record-sets --hosted-zone-id Z****************O --change-batch '{ "Comment": "created by QA_Jmeter LoadTest Job", "Changes": [ { "Action": "UPSERT", "ResourceRecordSet": { "Name": "main.loadtest.******.backend.******.****.****.******", "Type": "CNAME", "TTL": 300, "ResourceRecords": [ { "Value": "loadtest-aurora-backend-dev-instance-1.*************.*****.rds.amazonaws.com" } ] } } ] }'"""
sh"""aws route53 change-resource-record-sets --hosted-zone-id Z****************O --change-batch '{ "Comment": "created by QA_Jmeter LoadTest Job", "Changes": [ { "Action": "UPSERT", "ResourceRecordSet": { "Name": "ro.loadtest.******.backend.******.****.****.******", "Type": "CNAME", "TTL": 300, "ResourceRecords": [ { "Value": "loadtest-aurora-backend-dev-instance-2.*************.*****.rds.amazonaws.com" } ] } } ] }'"""
}
}
}добавляем скрипт в задание, сохраняем: 
Запускаем Build with Parameters, ставим галку в боксе CREATE_RDS_CLUSTER, далее жмем Build: 
В среднем создание(восстановление) RDS занимает 21-25 минуты может и больше, все зависит от размера кластера. Если создавать с нуля и накатывать дамп – будет намного дольше. Собственно результат выполнения смотрим ниже:
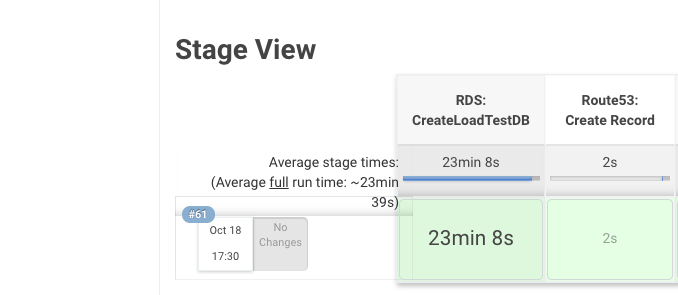
Проверяем RDS Cluster, AWS Console –> RDS:
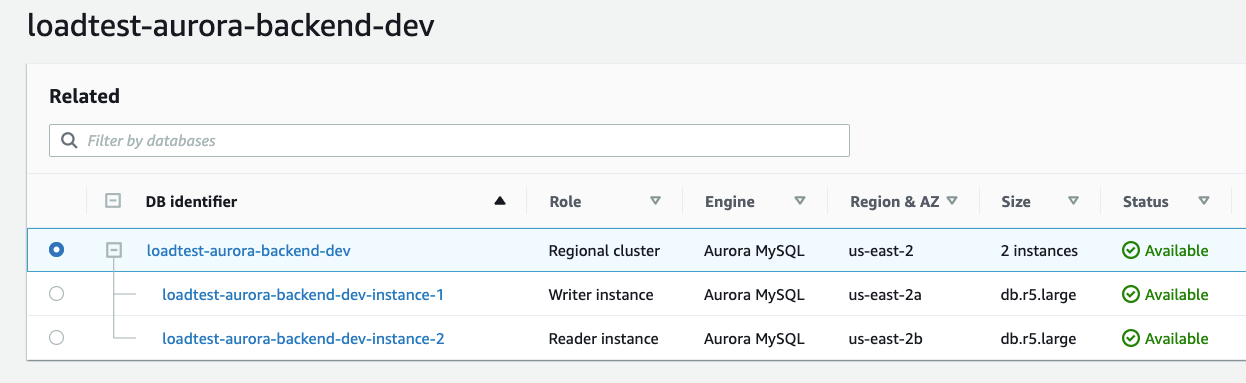
запись в Route53:
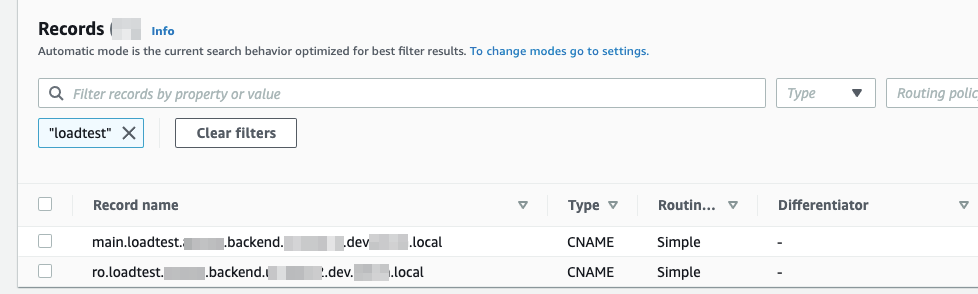
подключение к базе:
$ mysql -h main.loadtest.*****.backend.*****.dev.*****.local -u ***** -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
MySQL [(none)]> show databases;
+-------------------------+
| Database |
+-------------------------+
| information_schema |
| a***_****. |
| b****_***_** |
| mysql |
| sys |
| ***********. |
+-------------------------+
10 rows in set (0.017 sec)
MySQL [(none)]>Отлично базы все на месте, приступим к следующему этапу.
Подготовка к тестированию
Клонирование репозитория | генерация kube conf
Перед началом тестирования нужно выполнить подготовку. В подготовку входит:
- клонирование репозитория.
- генерация kubeconf файла для доступа к кластеру.
- выбор нужного файла и его расшифровка.
- копирование в под с jmeter-master.
- увеличение количества подов jmeter-slave.
Сначала добавим stage(‘Clone Repository’) который будет клонировать репозиторий, а после генерировать kubeconfig файл для доступа к кластеру, приступим.
Добавим параметры QA_REPO_URL, QA_REPO_BRANCH, AWS_EKS_CLUSTER:
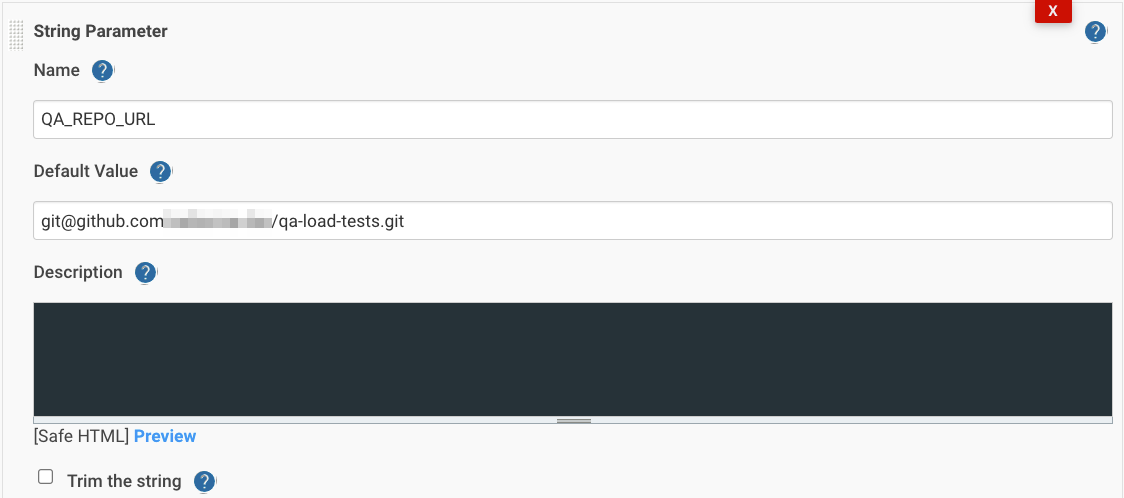
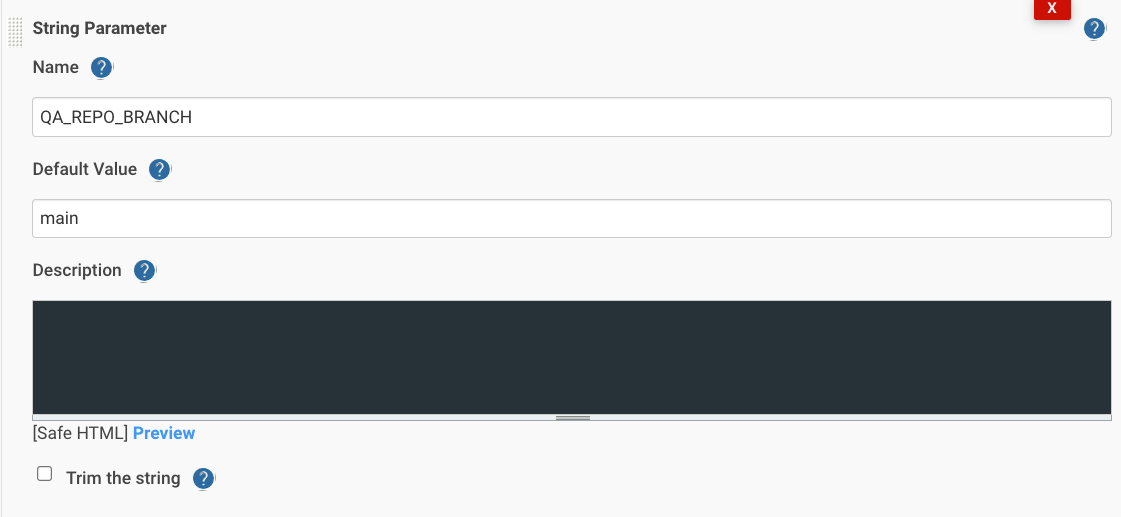
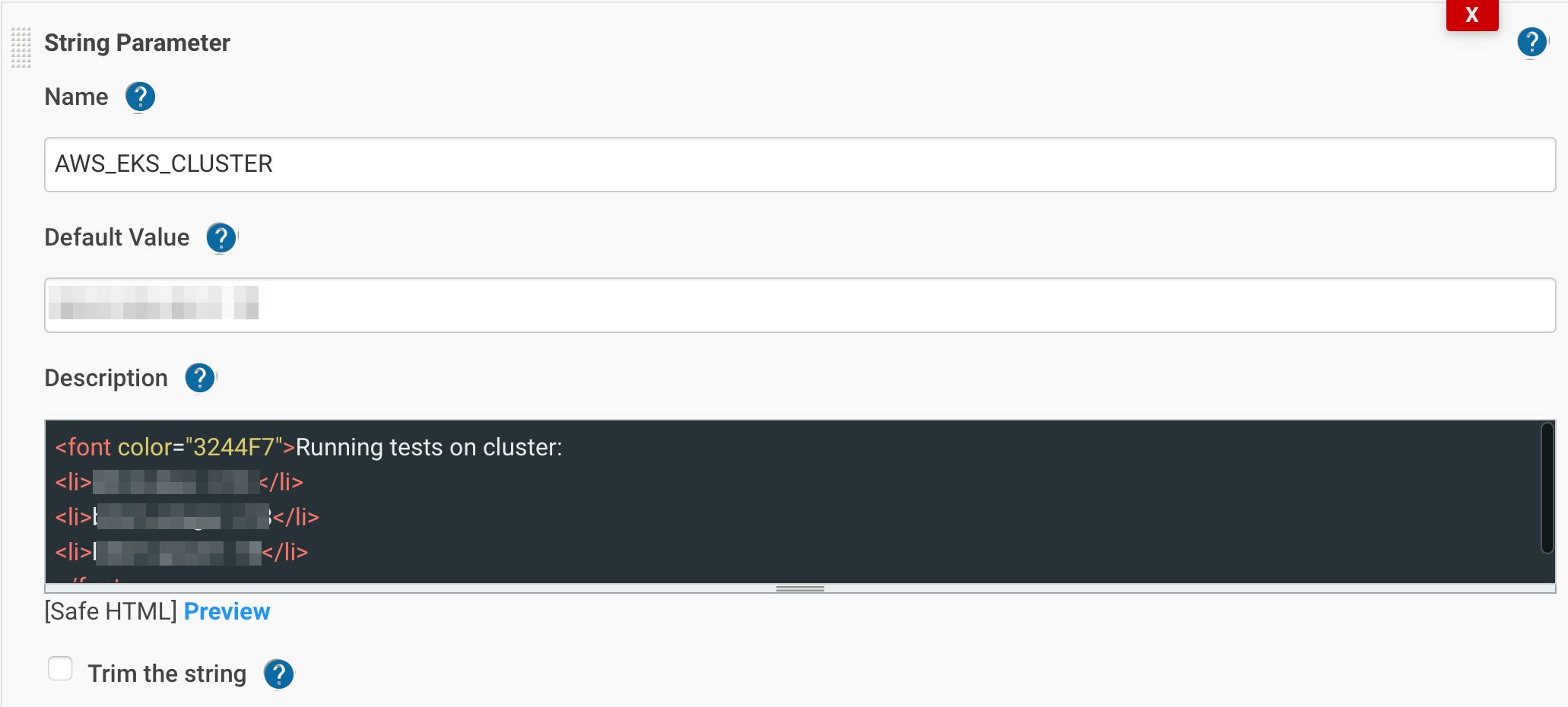
затем stage(‘Clone Repository’):
stage('Clone Repository'){
gitenv = git branch: "${QA_REPO_BRANCH}",
credentialsId: "j****-*********-github",
url: "${QA_REPO_URL}"
GIT_COMMIT_SHORT = gitenv.GIT_COMMIT.take(8)
sh "aws eks update-kubeconfig --region us-east-2 --name ${AWS_EKS_CLUSTER}"
sh "kubectl cluster-info"
}Выбор файла, дешифрование, копирование
Теперь нужно выбирать JMX файл, дешифровать его (как пользоваться sops можно почитать kms-aws-profiles) и cкопировать в под jmeter-master. Здесь нужно добавить два параметра:
- AWS_EKS_NAMESPACE – чтоб указывать namespace в котором задеплоен jmeter.
- JMETER_TESTPLAN_FILE – для выбора нужного файла JMX (в описании будет список доступных файлов).
После чего напишем небольшую функцию getPod() которая будет выводить список всех подов в неймспейсе, фильтровать, оставлять только название пода jmeter-master. Результат данной функции будем подставлять как env в нужных нам местах.
Добавляем параметры AWS_EKS_NAMESPACE и JMETER_TESTPLAN_FILE:
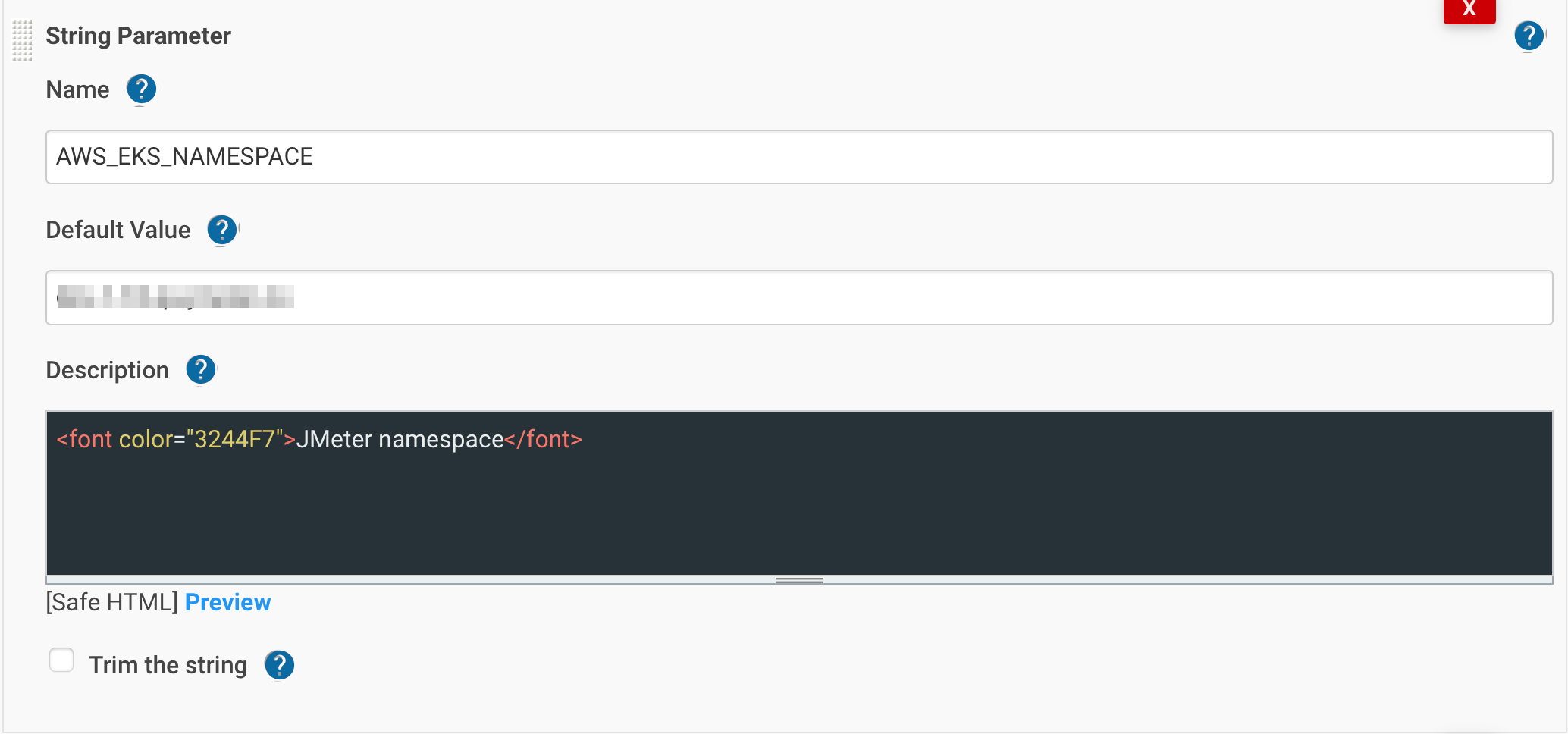
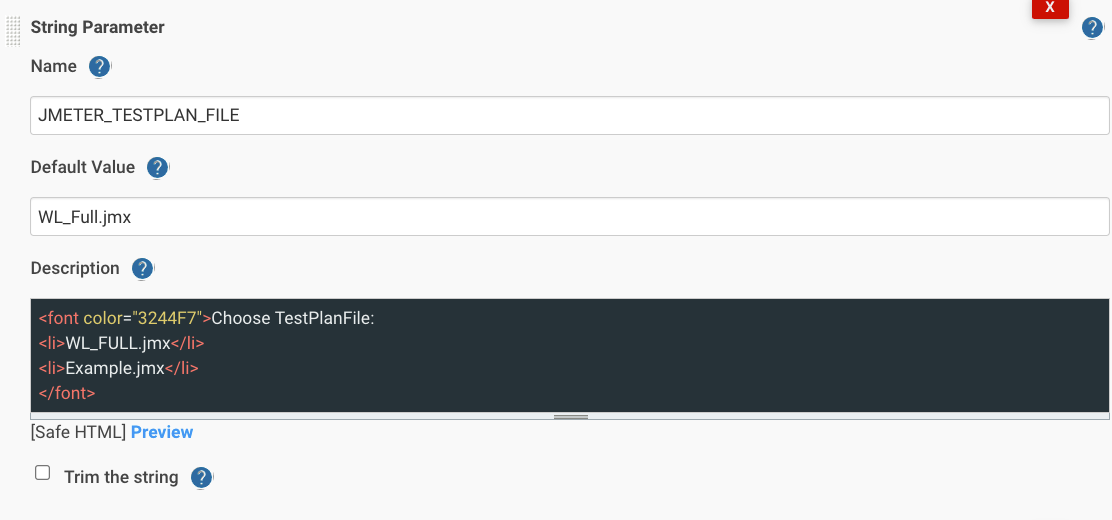
переходим к функции getPod() и stage(“Copy FileJMX to Jmeter-Master”):
def getPod(){
jmMaster = sh (returnStdout: true, script:"kubectl -n ****-qa-jmeter-*** get pods | grep jmeter-master | awk {'print \$1'} | tr -d '\n'")
}stage("Copy FileJMX to Jmeter-Master"){
getPod()
sh "sops --config .sops.yaml -d -i ${JMETER_TESTPLAN_FILE}" // decrypt testplan file
sh "kubectl -n ${AWS_EKS_NAMESPACE} cp ${JMETER_TESTPLAN_FILE} ${AWS_EKS_NAMESPACE}/${jmMaster}:/test/"
}хорошо, половину работы сделано.
Увеличение подов jmeter-slaves
Следующим этапом нужно увеличить нужное количество jmeter-slaves. Для увеличения используем команду kubectl scale deployment а после kubectl wait, чтоб дождаться статус подов Ready.
Добавим параметр JMETER_SLAVES_COUNT:
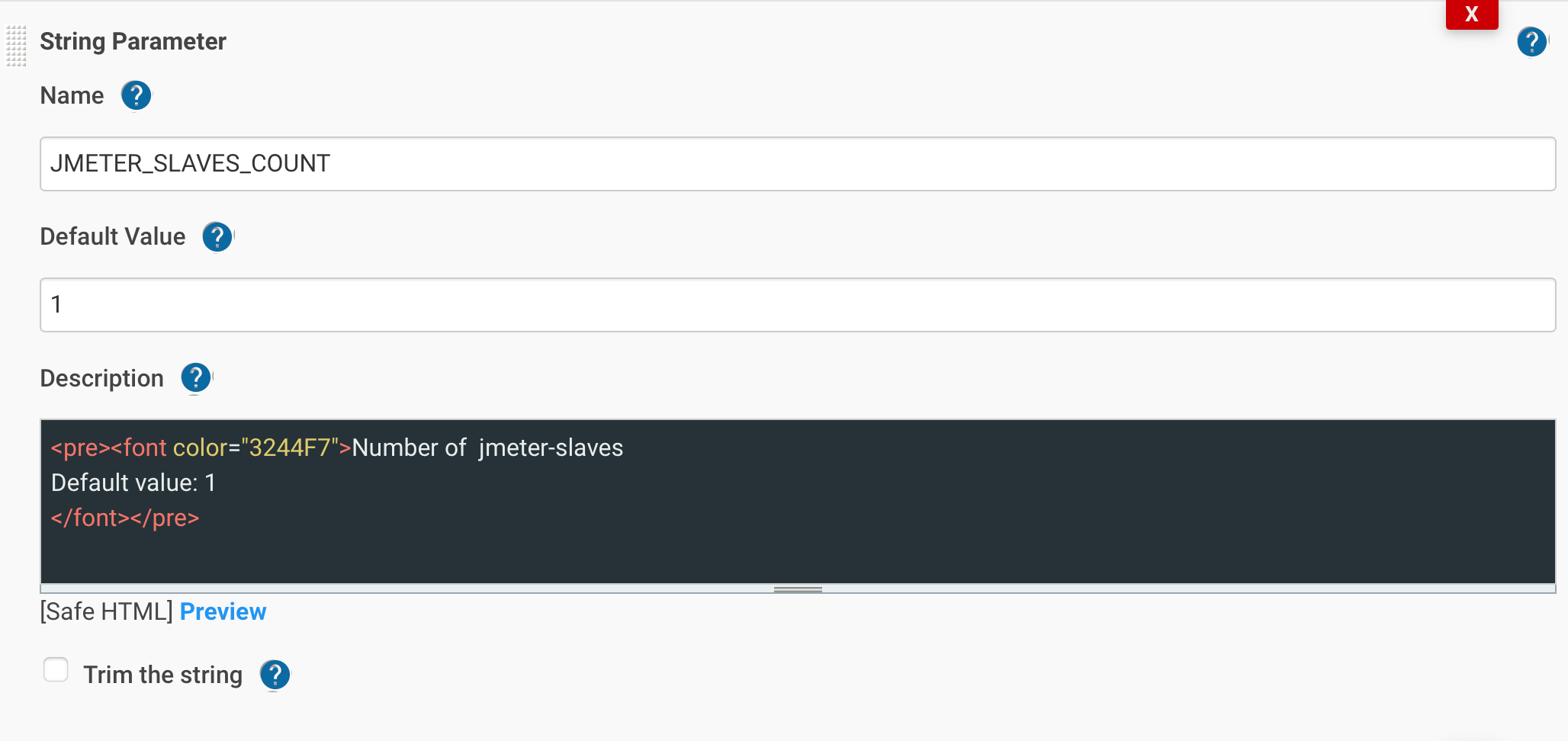
и stage(“Scale Up Jmeter-Slaves”):
stage("Scale Up Jmeter-Slaves"){
sh "kubectl -n ${AWS_EKS_NAMESPACE} scale deployment jmeter-slave --replicas=${JMETER_SLAVES_COUNT}"
sh "kubectl -n ${AWS_EKS_NAMESPACE} wait --all pods --for=condition=Ready --timeout=10m"
}Запуск нагрузочного тестирования
Мы все подготовили для запуска тестирования. Тесты будем запускать с помощью скрипта run-test.sh. Рассмотрим его детальней:
if [ "$ONE_SHOT" = "true" ]; then
until [ $(find ${TESTS_DIR}/ -type f | wc -l) -ne 0 ]; do # проверяет наличие файла в директории, если его нету будет ждать пока он не появиться
sleep 20
done
if [ -z ${SLAVE_IP_STRING} ]; then
SLAVE_IP_STRING=`getent ahostsv4 ${SLAVE_SVC_NAME} |awk '!($1 in a){a[$1];printf "%s%s",t,$1; t=","}'` # здесь виводит список jmeter-slaves вместе с IP и фильтрут оставляя только IP адреса
fi
for file in ${TESTS_DIR}/*.jmx ; do
jmeter -n -t ${file} -Jserver.rmi.ssl.disable=${SSL_DISABLED} -R ${SLAVE_IP_STRING} # берет все файли с расширением jmx и запускает тесты
done
else
echo "Wait for manual run."
while true ; do
sleep 60
done
fiКонечно скрипт можно модифицировать или вообще избавиться от него (при сборке образа), но меня все устраивает. Команда которой будем запускать скрипт в поде выгладит так:
- kubectl exec -i -n ${AWS_EKS_NAMESPACE} ${jmMaster} — sh -c ‘ONE_SHOT=true; /run-test.sh’.
Лучше после завершения тестирования ничего не оставлять=), будем удалять файл с пода и останавливать тесты на слейвах (для чего это нужно описано в конце поста).
Добавляем stage(“Run LoadTesting”) и описываем его:
stage("Run LoadTesting"){
// run jmeter test
sh "kubectl exec -i -n ${AWS_EKS_NAMESPACE} ${jmMaster} -- sh -c 'ONE_SHOT=true; /run-test.sh'"
// delete TestPlanFile from Pod
sh "kubectl -n ${AWS_EKS_NAMESPACE} exec ${jmMaster} -- rm -rf /test/${JMETER_TESTPLAN_FILE}"
// Run the Shutdown client to stop a non-GUI instance gracefully
sh "kubectl -n ${AWS_EKS_NAMESPACE} exec ${jmMaster} -- sh -c '/opt/jmeter/bin/shutdown.sh'"
}Что ж, приступим к запуску.
Жмем Build with Parameters, указываем количество jmerer-slave, выберем файл с тестами, после жмем Build:
смотрим output:
.....
15:44:47 [Pipeline] { (Run LoadTesting)
15:44:47 [Pipeline] sh
15:44:47 + kubectl exec -i -n ******-qa-jmeter-**-** jmeter-master-866ffb549d-pph64 -- sh -c ONE_SHOT=true; /run-test.sh
15:44:52 Creating summariser <summary>
15:44:52 Created the tree successfully using /test/WL_Full.jmx
15:44:52 Configuring remote engine: 10.21.51.89
15:44:52 Starting distributed test with remote engines: [10.21.51.89] @ Wed Oct 27 12:44:52 GMT 2021 (1635338692109)
15:44:55 Remote engines have been started:[10.21.51.89]
15:44:55 Waiting for possible Shutdown/StopTestNow/HeapDump/ThreadDump message on port 4445
15:45:05 summary + 1 in 00:00:09 = 0.1/s Avg: 653 Min: 653 Max: 653 Err: 0 (0.00%) Active: 4 Started: 4 Finished: 0
15:45:31 summary + 4 in 00:00:26 = 0.2/s Avg: 632 Min: 123 Max: 1094 Err: 0 (0.00%) Active: 12 Started: 12 Finished: 0
15:45:31 summary = 5 in 00:00:35 = 0.1/s Avg: 636 Min: 123 Max: 1094 Err: 0 (0.00%)
15:46:03 summary + 600 in 00:00:32 = 18.7/s Avg: 596 Min: 34 Max: 8565 Err: 35 (5.83%) Active: 20 Started: 20 Finished: 0
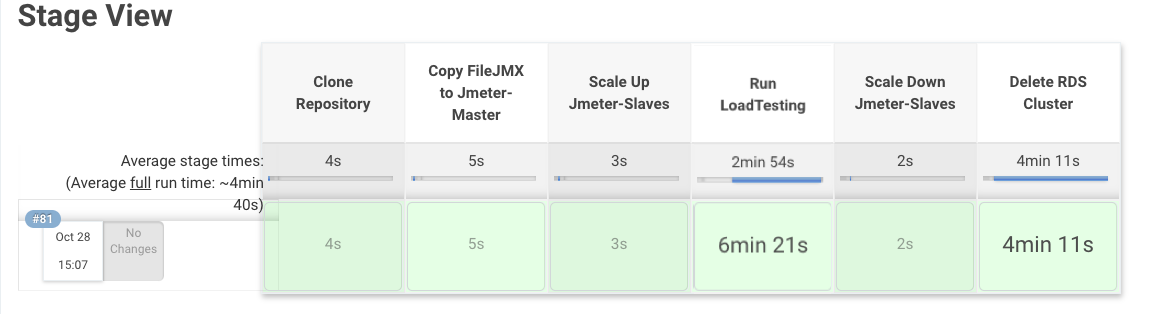
****тесты запустились, ждем завершения, после посмотрим всю последовательность прохождения:
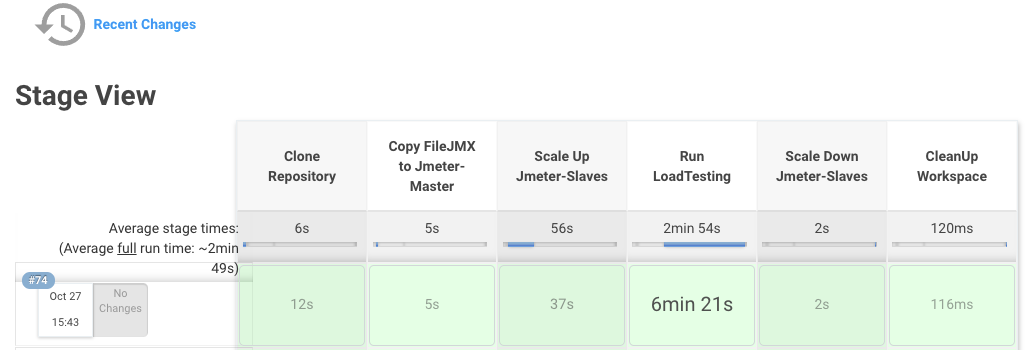
и результат тестов в Grafana:
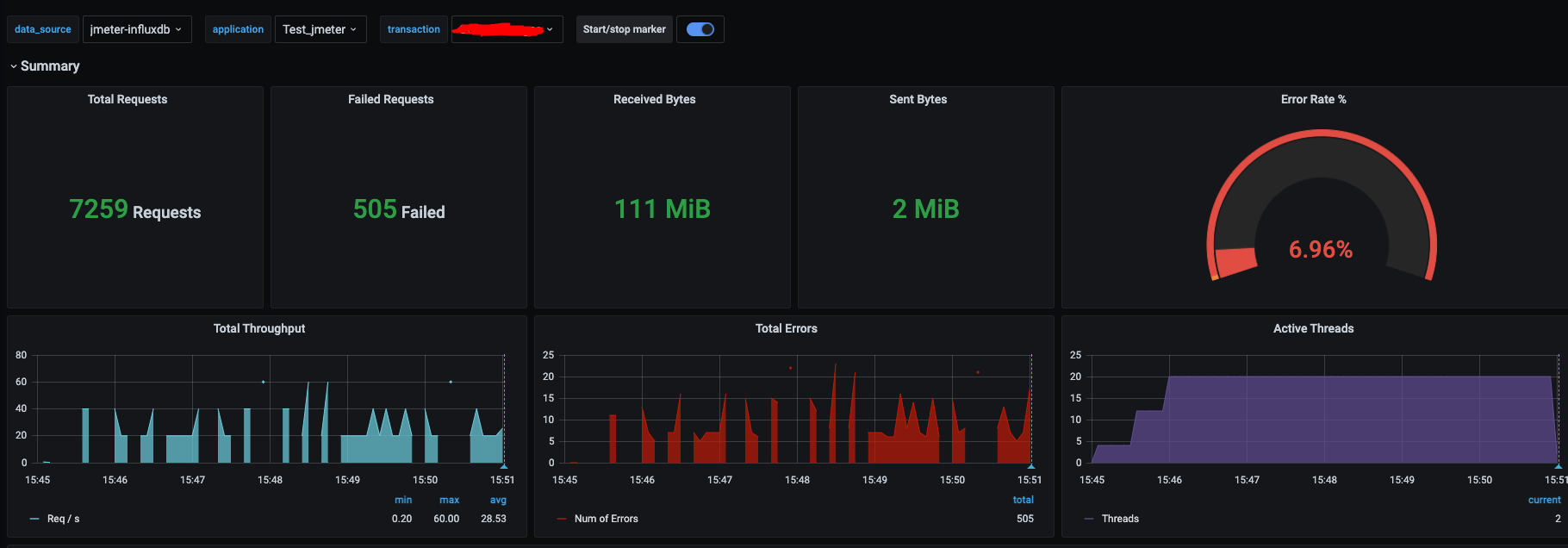 Отлично.
Отлично.
Результат Тестирования
Так как же нам вывести время? как добавить его в URL в нужное место?
Первое, что пришло на ум – использовать команду date, команда позволяет показать текущую дату и время в терминале.
Осталось найти нужный формат времени который использует Grafana. Поискав немного нашёл то что нужно: date and time YYYYMMDDTHHmmss from=20211029T154321 to=20211029T154620.
Проверим как работает команда date, главное чтоб в %Y%m%dT%H%M%S не было никаких разделителей кроме буквы T (для обозначения, что далее идет время), запустим ее:
date +%Y%m%dT%H%M%S 20211029T154321
Хорошо, напишем две функции.
- первая – функция с именем startTime(), она выводит время начала тестирования, ee будем вызывать в stage(“Run LoadTesting”)
- вторая – функция с имене endTime(), которою вызываем в stage(“Scale Down Jmeter-Slaves”) и она показывает время окончание.
Добавляем функции:
def startTime(){
start = sh (returnStdout: true, script:"echo `date +%Y%m%dT%H%M%S` | tr -d '\n'") // tr -d '\n' - убираем все пробелы, чтоб остался только результат
}
def endTime(){
end = sh (returnStdout: true, script:"echo `date +%Y%m%dT%H%M%S` | tr -d '\n'")
}вызываем их в стейджах:
....
stage("Run LoadTesting"){
startTime()
sh "kubectl exec -i -n ${AWS_EKS_NAMESPACE} ${jmMaster} -- sh -c 'ONE_SHOT=true; /run-test.sh'"
// delete TestPlanFile from Pod
sh "kubectl -n ${AWS_EKS_NAMESPACE} exec ${jmMaster} -- rm -rf /test/${JMETER_TESTPLAN_FILE}"
sh "kubectl -n ${AWS_EKS_NAMESPACE} exec ${jmMaster} -- sh -c '/opt/jmeter/bin/shutdown.sh'"
}
stage("Scale Down Jmeter-Slaves"){
endTime()
sh "kubectl -n ${AWS_EKS_NAMESPACE} scale deployment jmeter-slave --replicas=1"
sh "kubectl -n ${AWS_EKS_NAMESPACE} wait deployment/jmeter-slave --for=condition=available"
}
....и добавим stage(“ShowTestResult”), указав переменные в from=${start} и to=${end}, таким образом результаты функций будут подставляться через переменную в URL и мы получим ссылку на результат за нужный период времени:
stage("ShowTestResult"){
echo "https://***-**-***-qa.jmeter.*****/d/PIQCKqO7k/apache-jmeter-dashboard-using-core-influxdbbackendlistenerclient?orgId=1&from=${start}&to=${end}&var-data_source=jmeter-influxdb&var-application=Test_jmeter&var-transaction=GET%20challenges&var-measurement_name=jmeter&var-send_interval=5"
}запускаем задание, ждем его завершения и ищем в Console Output stage(“ShowTestResult”):
....
16:38:09 [Pipeline] stage
16:38:09 [Pipeline] { (ShowTestResult)
16:38:09 [Pipeline] echo
16:38:09 https://***-****-qa.jmeter.*******/d/PIQCKqO7k/apache-jmeter-dashboard-using-core-influxdbbackendlistenerclient?orgId=1&from=20211029T133148&to=20211029T133806&var-data_source=jmeter-influxdb&var-application=Test_jmeter&var-transaction=GET%20challenges&var-measurement_name=jmeter&var-send_interval=5
16:38:09 [Pipeline] }
16:38:09 [Pipeline] // stage
16:38:09 [Pipeline] }
....переходим по ссылке:
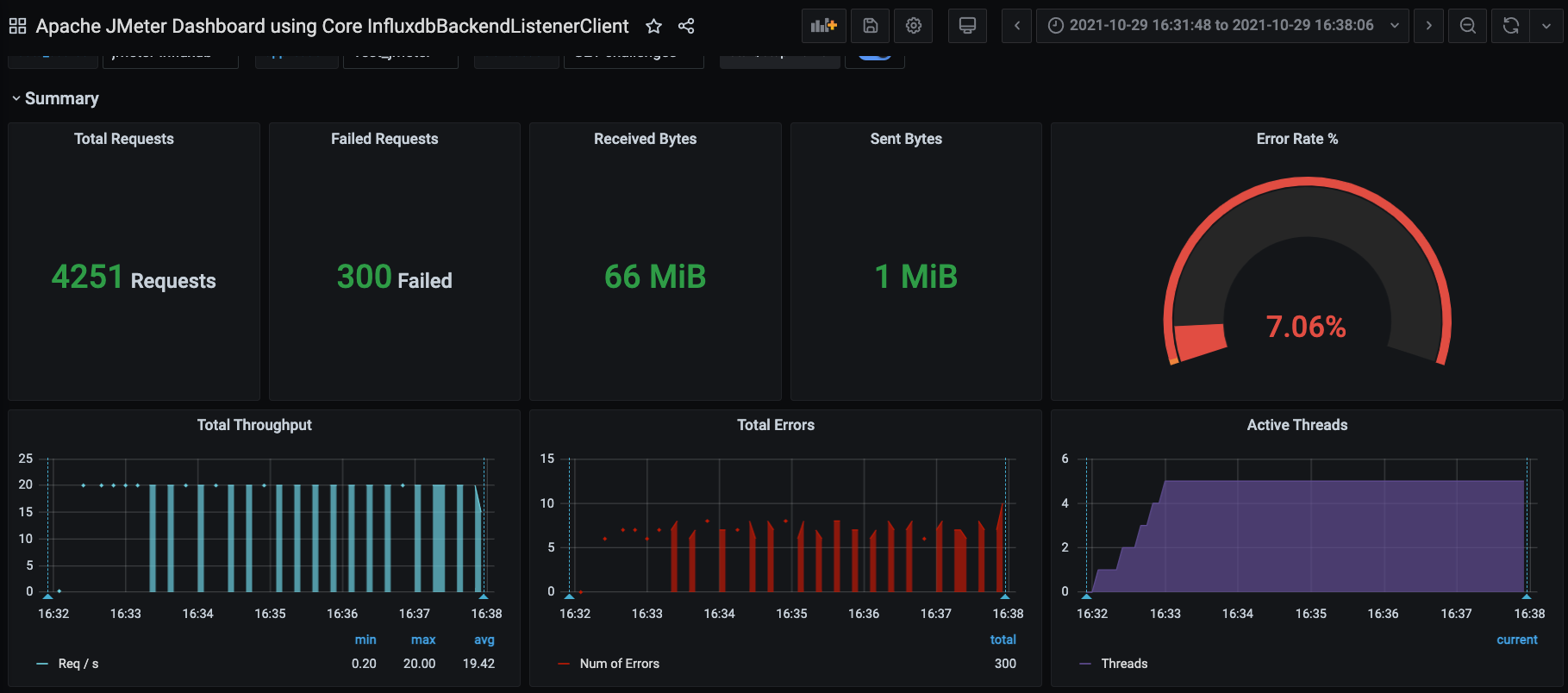
как видим открыта борда с результатом за нужный период времени):
Удаление RDS Cluster
Когда тестировать больше ненужно, удаляем созданий кластер RDS. Для этого добавим stage(“Delete RDS Cluster”) и условие if (env.DELETE_RDS_CLUSTER.toBoolean()). При запуске финального тестирования, будем ставить галочку в боксе DELETE_RDS_CLUSTER, после того как заданные выполнит все стейджи, в конце будет вызван стейдж удаления.
Для удаления используем aws-cli:
- aws rds delete-db-instance – удаления RDS инситансов.
- aws rds wait db-instance-deleted – будем ждать пока статус инстансов будет deleted.
- aws rds delete-db-cluster – удаление самого кластера.
- Запись CNAME будет удалиться автоматически!
Добавим параметр DELETE_RDS_CLUSTER:
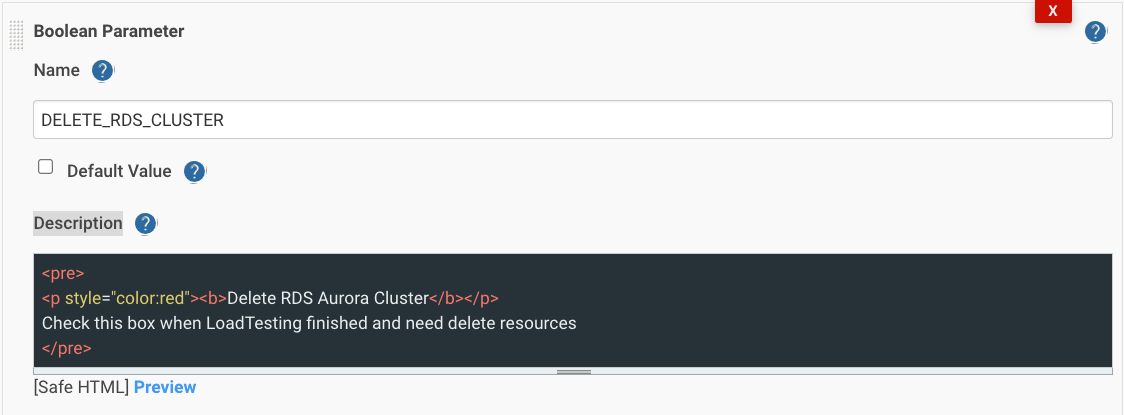
и условие if (env.DELETE_RDS_CLUSTER.toBoolean()) с stage(“RDS: Delete CLuster”):
if (env.DELETE_RDS_CLUSTER.toBoolean()){
stage("Delete RDS Cluster"){
echo "========================== AWS RDS: delete RDS Instance ==========================="
sh "aws rds delete-db-instance --skip-final-snapshot --db-instance-identifier loadtest-aurora-backend-dev-instance-1"
sh "aws rds delete-db-instance --skip-final-snapshot --db-instance-identifier loadtest-aurora-backend-dev-instance-2"
echo "===================== AWS RDS: Wait when DB have been deleted ======================"
sh "aws rds wait db-instance-deleted --db-instance-identifier loadtest-aurora-backend-dev-instance-1"
sh "aws rds wait db-instance-deleted --db-instance-identifier loadtest-aurora-backend-dev-instance-2"
echo "======================== AWS RDS: delete RDS Cluster ========================="
sh "aws rds delete-db-cluster --db-cluster-identifier loadtest-aurora-backend-dev --skip-final-snapshot"
}
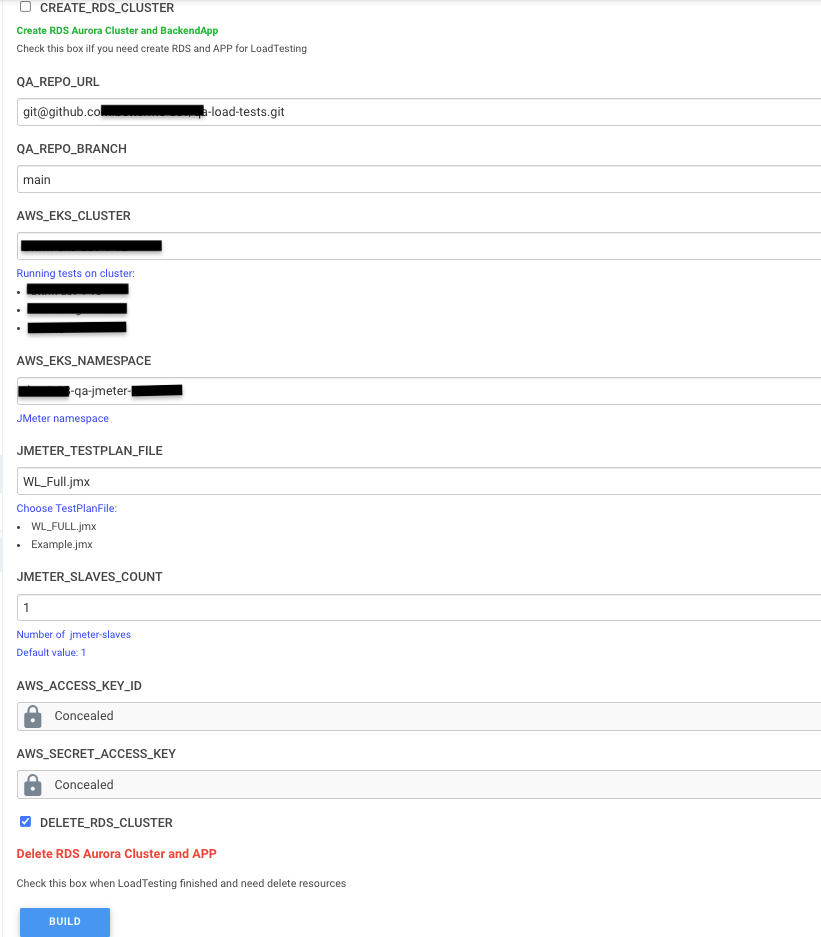
}Осталось произвести финальный запуск тестирования. Перед запуском посмотрим все параметры которые мы добавили, поставим галку DELETE_RDS_CLUSTER, запустим нажав Build:
Ошибки
Engine is busy – please try later
Задание после нескольких запусков перестало отрабатывать. Посмотрев логи увидел следующее:
.... 11:02:27 + kubectl exec -i -n ***-***-qa-jmeter-** jmeter-master-866ffb549d-8g7bw -- sh -c ONE_SHOT=true; /run-test.sh 11:02:31 Creating summariser <summary> 11:02:31 Created the tree successfully using /test/WL_Full.jmx 11:02:31 Configuring remote engine: 10.21.53.212 11:02:31 Starting distributed test with remote engines: [10.21.53.212] @ Fri Oct 29 08:02:31 GMT 2021 (1635494551279) 11:02:32 Engine is busy - please try later 11:02:33 The following remote engines have not started:[10.21.53.212] 11:02:33 Waiting for possible Shutdown/StopTestNow/HeapDump/ThreadDump message on port 4445 ....
Проблема возникает когда тест не остановлен, на jmeter-slave все еще запущен процесс с предвидущего тестирования. Есть несколько решений:
- 1. Можем после завершения stage(“Run LoadTesting”), заскейлить поды слейва в 0. При новом запуске тестов будет создаваться новый под и задание отработает без ошибок.
- 2. Добавить команду, которая будет останавливать процессы тест плана на слейвах. Для этого необходимо запустить скрипт shutdown.sh на jmeter-master который находиться в директории /opt/jmeter/bin/, что мы и сделали выше.
Полезные ссылки
- https://github.com/grafana/helm-charts
- https://github.com/influxdata/helm-charts
- https://docs.aws.amazon.com/cli/latest/reference/rds
- https://kubernetes.io/ru/docs/reference/kubectl/cheatsheet
- https://jmeter.apache.org
- https://www.lifewire.com/display-date-time-using-linux-command-line-4032698